How Snapshot and Delta Storage Differs
A bank statement analogy exemplified through the lens of Subversion and Git!


If you've worked with version control systems other than Git, like Perforce or Subversion, you've probably pondered why Git uses snapshots over deltas when storing changes.
Or, if you're new to version control, and Git is your first encounter, thinking delta storage would be the preferred option isn't far-fetched. After all, only storing a portion of a file or codebase, the delta change, must be much more clever than recording the entire file structure each time — right?
In this post, we'll look at how snapshot and delta storage differs from a general perspective and, more specifically, how it's implemented in version control. In the latter case, we'll compare Subversion to Git using a bank statement analogy.
Snapshot vs Delta storage
Generally, we can define the differences between a snapshot and delta storage like this.
🎞️ Snapshot storage saves the entire state of a file or system as a single instance, known as a snapshot. Each snapshot represents the system at a given time and serves as a reference point for future changes. This method is simple, efficient, and straightforward, but it can consume a lot of storage space over time if there are frequent changes to the system.
Δ Delta storage, on the other hand, saves only the changes made to a file or system rather than the entire state. Each change is stored as a delta or a difference from the previous version, and the system's current state is reconstructed by combining all the deltas. This method is more efficient in terms of storage space, as it only stores the differences between versions but can be more complex to implement and manage.
Choosing between the two options from a software development perspective, where "frequent changes" are part of the game, delta storage should, in theory, be the better-suited alternative — right?
So why did Linus Torvalds — the man behind both Linux and Git — opt for snapshot storage when designing Git? And how did he mitigate the potential downside of ending up with an exponentially increasing storage space as new versions of a project are added?
Before we answer those questions, let's examine the two alternatives using a bank statement analogy.
💵 A bank statement analogy
If we forget software development for a while and look at the two storage options from a bank statement perspective, their differences become even more apparent.
Consider your current account for a moment; frequently used to deposit and withdraw money. To keep track of the actual balance of your account, banks typically store the latest — current amount — rather than keeping track of changes in the form of deltas. After all, your account's balance represents the money in the bank at a particular moment rather than the transaction history.

Hence, it makes more sense to store the current balance of your account as a snapshot rather than as cumulative deltas. The snapshot provides a clear, straightforward representation of the state of your account, which can be easily accessed and used for various purposes, such as reporting, accounting, or producing a statement over last month's transactions. In addition, the new balance, as a whole, is recorded together with a datestamp whenever a deposit or withdrawal is made.
That said, let's see how the state of your current account would be kept if the balance is stored in a plain text file, using Subversion or Git to record the transactions!
Logging transactions with Subversion and Git
Starting with two empty repositories containing a single branch, with no commits (transactions) created so far, the version history in Subversion and Git don't differ — they're just empty!
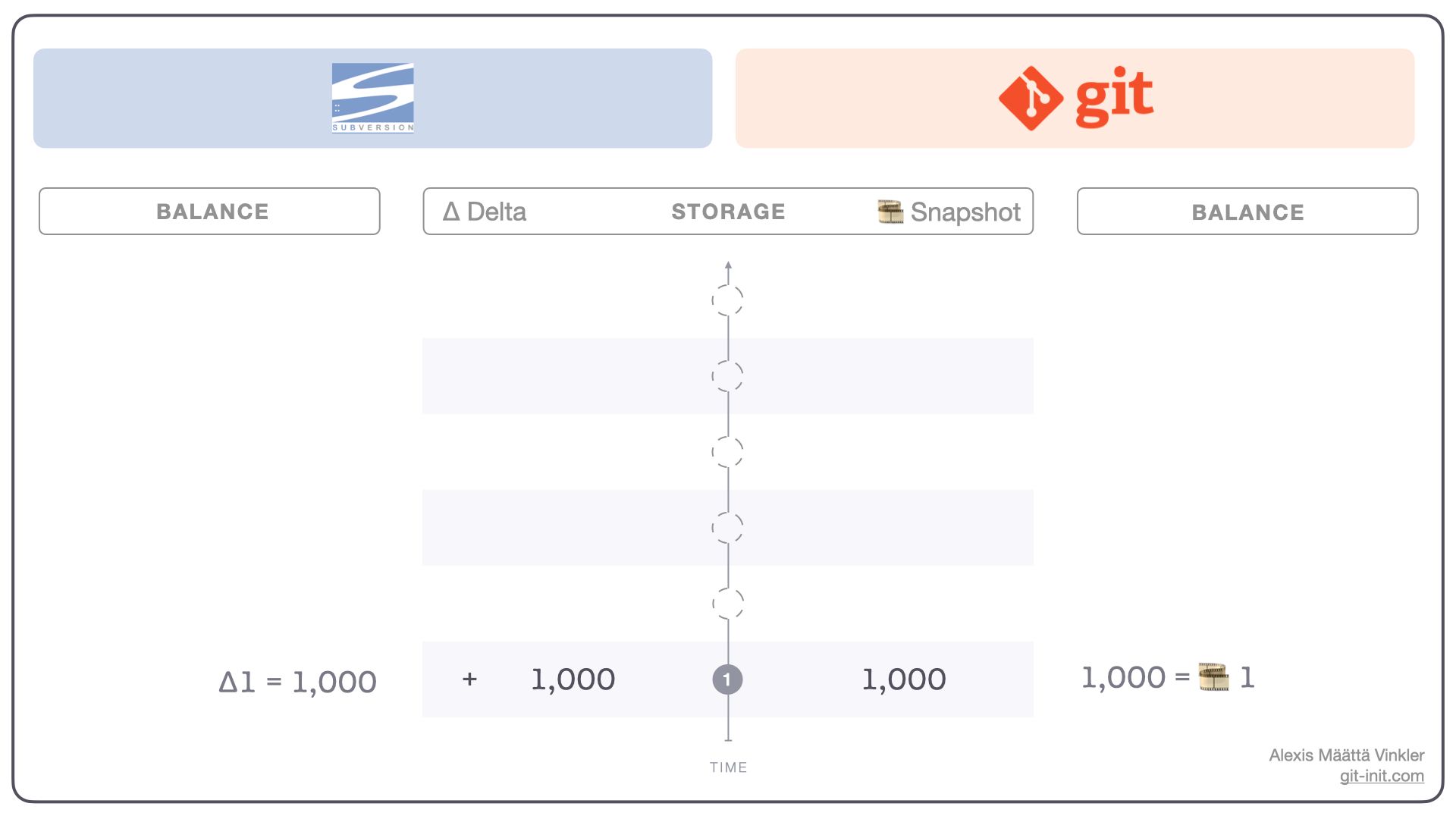
If we create a new file called balance.md with the intended use to keep track of our current account balance, we can then add a single line to it representing an initial deposit of, let's say $1.000. By committing it, the two histories still look identical! Why? Subversion recorded the delta change, which in this case was a file creation containing an $1.000 entry (with no previous history), while Git did roughly the same thing — stored a snapshot containing the same file and contents.
By making consecutive transactions (commits), one per day, over the following five days, our two distinct histories will look radically different. That's because Subversion keeps recording the delta change, while Git stores the actual snapshot in every commit. Check out the complete commit history below!
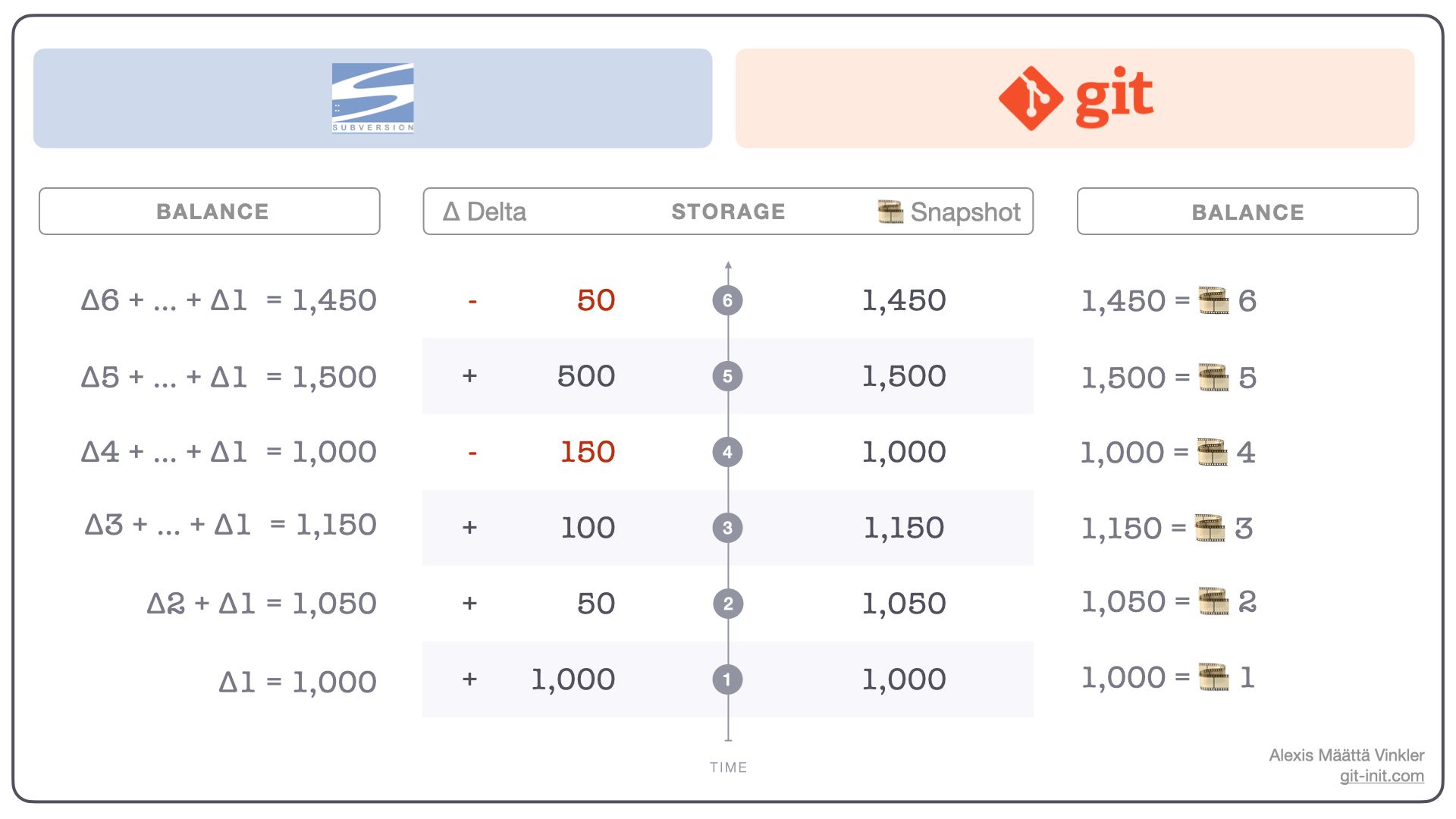
Note: The exact implementation details of Subversion's delta storage mechanism can differ depending on version, as all changes are stored and managed centrally. This is just a generalization of how it could work.
So what's the benefit of using either or? Mainly how the balance on a particular day is retrieved and the implications it has in a broader perspective, for example, when comparing differences between days (commits).
Comparing balances between days
Given our six-day transactional history, it's obvious how getting the balance for a particular day differs between the two solutions.
Retrieving the balance of day 6
- Delta: Δ6 + Δ5 + Δ4 + Δ3 + Δ2 + Δ1 = 1,450
- Snapshot: 🎞️6 = 1,450
As you can see, getting the balance of day six from Git is just a matter of reading the snapshot on that particular day, while in Subversion, every change leading up to day 6 has to be added up to get to the final value. But, reading the balance is one thing; if we instead want to see how it changed between two different days, how would that work?
Comparing the balance between days 4 & 2
- Delta: (Δ4 + Δ3 + Δ2 + Δ1) - (Δ2 + Δ1) = -50
- Snapshot: 🎞️4 - 🎞️2 = -50
Again, in the delta case, the balance of days 4 and 2 must be computed before they can be compared. With Git, each snapshot can be retrieved and compared directly to the other — quick and easy!
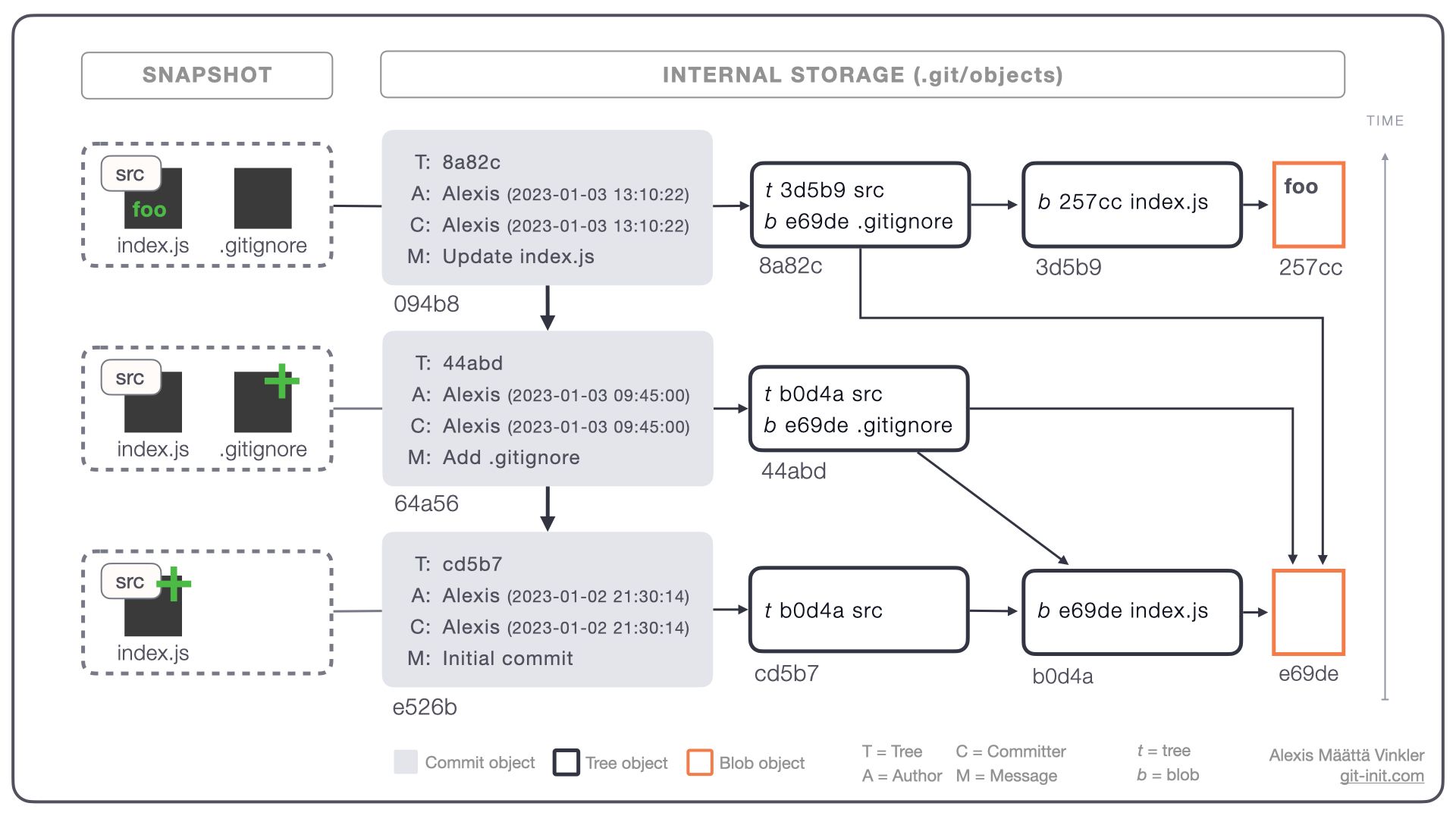
Git's snapshot implementation
Let's get back to our initial question about why Linus Torvalds opted for snapshot storage when designing Git. Through Git's implementation, it turns out he could provide a simple, efficient, and transparent method of version control that is well-suited for the distributed nature of software development — something he thought delta storage could not compete with.
Are you intrigued by Git's snapshot-storing mechanism and want to know more? Then, check out the post below and learn the inner details of it — I promise it'll improve your general understanding and make you more productive working with Git!
Key takeaways
- Each snapshot represents all tracked files in the codebase at a given time; deltas only contain information about what changed from a previous version.
- With snapshot storage, you can instantly compare any two snapshots without first calculating their nets. Heck, even the comparison order can be reversed in no time:
$ git diff <commit-1> <commit-2>or$ git diff <commit-2> <commit-1> - With snapshot storage, diffs are computed on the fly.
- Snapshot storage is straightforward but can consume more space than delta storage if not implemented cleverly; delta storage, on the other hand, can be more complex to implement and manage but consumes less space.
😎 Thanks for reading, and good luck improving your source code management skills!
If you'd like more pieces like this, subscribe to the news feed, so you don't miss anything! By subscribing, you'll also get access to members-only content!
If you have any questions or suggestions, try reaching me on Twitter – @Stjaertfena