How Git Store Files — a concrete example
Want to know how Git stores files and folders? Check out this concrete step-by-step walkthrough!

This is a follow-up post to How Does Git Store Files? — which looked at file storage from a conceptual point of view. In this one, we'll instead view it from a concrete hands-on perspective, where you can even follow along step-by-step locally if you'd like!
I assume by now you're already familiar with Git's internal object types Commit, Tree, and Blob, and that you know what structures DAG and hash-map are; if not, then revisit the article mentioned above.
For the object types, let's just remind ourselves quickly:
- Commit: Immutable snapshot of your entire project at a given time, reproducible from its root tree.
- Tree: Internal representation of a project folder, responsible for keeping track of its direct files and subfolders; can reference other trees and blobs.
- Blob: Binary Large Object (blob) acting as an internal container storing file contents, unaware of what file or files it represents.
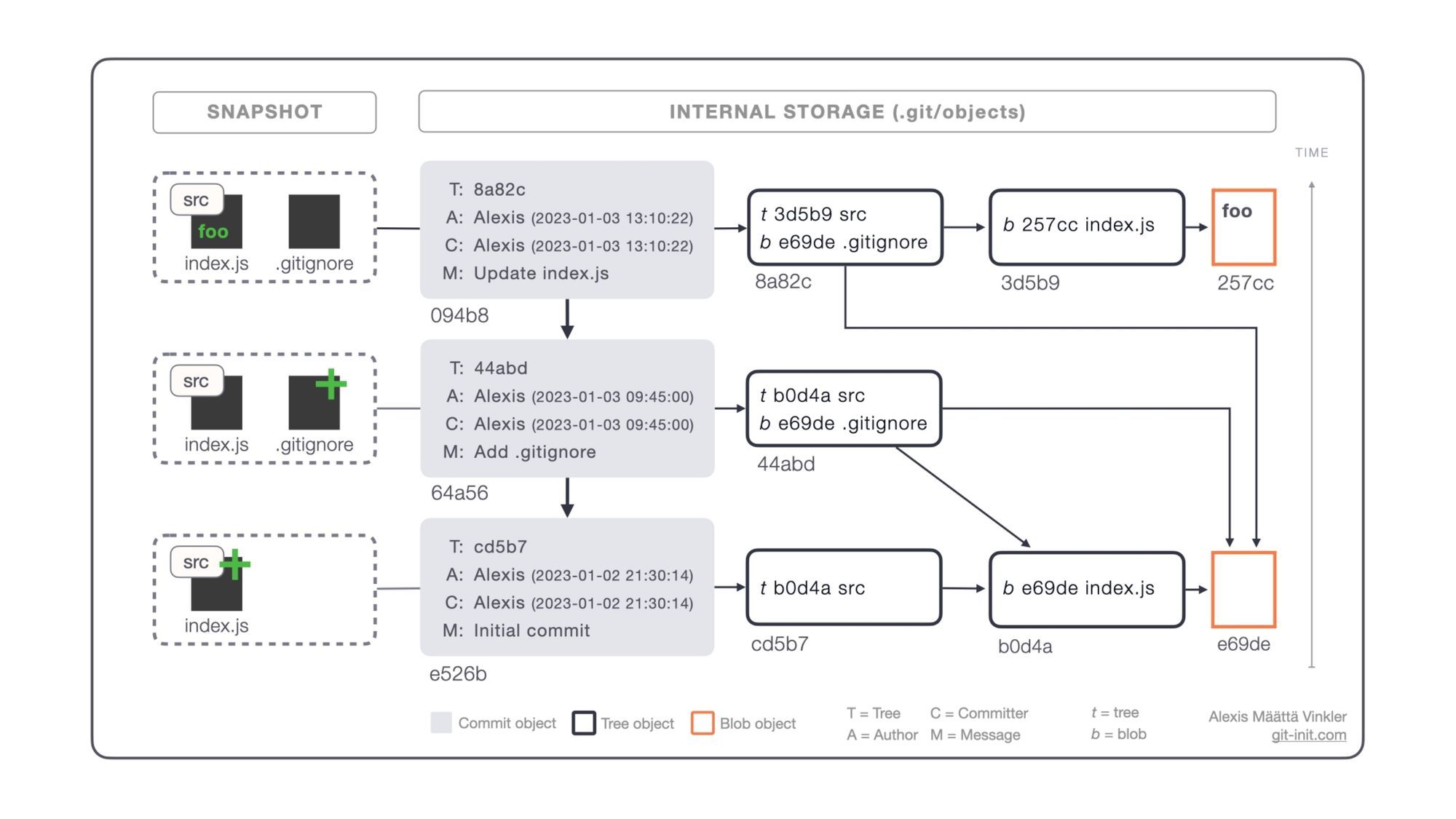
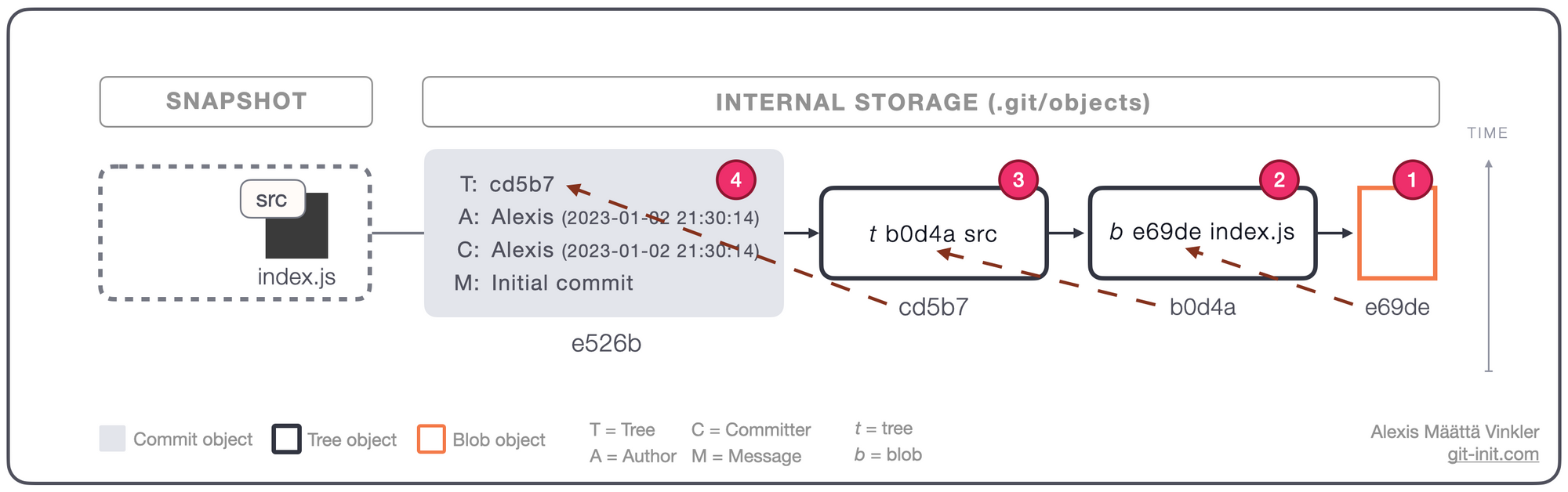
You probably recognize the below infographic from the previous post, illustrating how a single initial commit is stored. But what happens if we add consecutive commits, and make modifications to already tracked files? That's what we're gonna look into in this post, as promised, from a concrete commit perspective!
This post is for members only, sign up to get instant access. Only a valid e-mail is required!
File storage through commits
Given our conceptual model from before, let's see how the giant hash-map-powered DAG, based on Git's core object types Commit, Tree, and Blob, are used in combination to store your project files and folders!