How Does Git Store Files?
In this post, I'll show you how project files and folders are stored, and how they relate to the overarching commit history — all from a conceptual point of view.


If you've been working with Git for while you've probably at some point asked yourself the question "How does Git store files (and folders)?".
Whatever your reasons, having a good conceptual understanding of how it works makes your life with Git more enjoyable and productive, particularly since it unveils how commits are indeed immutable snapshots — a fundamental cornerstone in Git's design.
In this post, I'll show you how project files and folders are stored, and how they relate to the overarching commit history — all from a conceptual point of view.
What Git technically is
From the official manual ($ man git) and Pro Git Book we get the following queues about Git's internal data storage or object store as it's also called.
Git is a content-addressable filesystem. Great. What does that mean? It means that at the core of Git is a simple key-value data store. What this means is that you can insert any kind of content into a Git repository, for which Git will hand you back a unique key you can use later to retrieve that content. — Pro Git, Chacon & Straub
As we can see from the two descriptions "content is key" in Git (pun intended 😆), but what does it mean and how does it work? It's something we need to address before the main question about file storage can be answered.
Content is Key
Git's internal object store is a giant hash map (or dictionary) where key-value pairs are used to keep track of anything added to it; physically it's located in the ./git/objects folder in each repo.
To ensure data integrity any content (value) inserted into Git is digested using a cryptographic hash function, where the resulting hash becomes the key to the just inserted value (object); these keys are in Git referred to as object-ID:s or SHA-ID:s (from the name of the SHA algorithm used). In general cryptography terms, these keys are known as checksums as they can be used to validate the integrity of the hashed value — an important aspect if you would like to keep track of file versions in a distributed system like Git.
What makes Git's storage so clever is that it combines this basic checksum-based dictionary with another data structure known as a DAG (Directed Acyclic Graph). A DAG is tailor-made to model systems that have a logical ordering, such as a workflow or a set of tasks to be completed in a specific order, or to understand how different pieces of information are related (like versions of a file).
Conceptually a DAG in mathematics and computer science is a graph where all nodes (or objects as Git calls them) are arranged in a way that all edges (references between objects) never form a closed loop; i.e. these references only flow in one direction — just like our commit history!
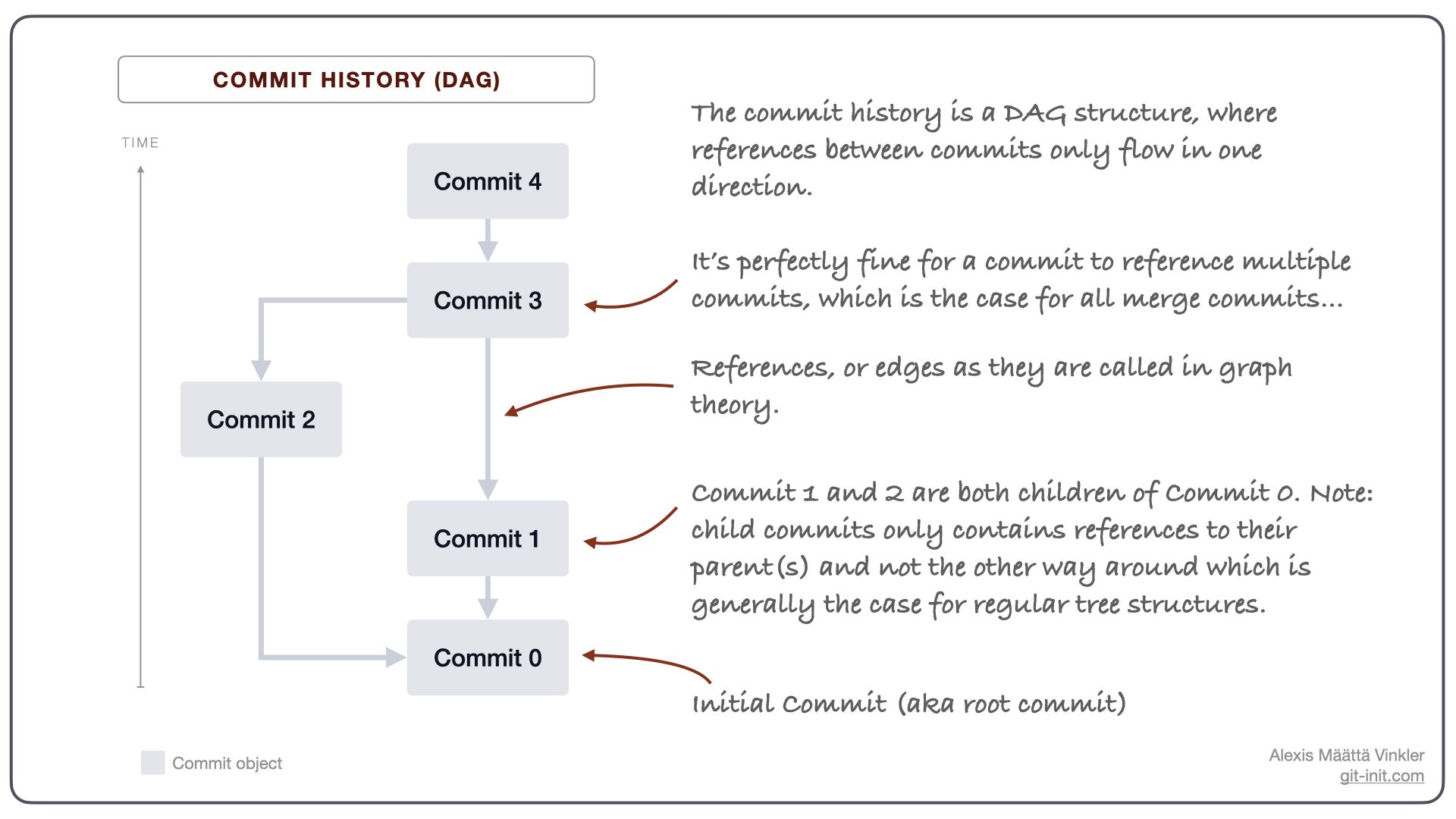
So what does any of this have to do with the original question "How Does Git Store Files?" — Well, it turns out that not only is Git using the DAG as a structure for our commits, but for our stored files and folders as well!
Instead of Commit objects, Git uses Trees and Blobs to persist our files and folders.
Git's core object types: Commit, Tree, and Blob
To understand how a project snapshot is stored within a commit, one must acknowledge the different types of internal objects Git use for storing content, which are Commit, Tree, and Blob.
- Commit: Immutable snapshot of your entire codebase at a given time; formally called commit object. Every commit, but the root commit (i.e. your initial commit), contains a reference to its parent commit (or commits if being a merge commit) and the root tree which makes up the base of the project snapshot. It also contains metadata about who the author and committer were (including a time stamp for each) and a commit message.
- Tree: A tree object is responsible for keeping track of file names and folders. A tree can reference other trees (subfolders) or blobs (file content), but a single tree only holds information about its direct content (i.e. direct children if viewed from a folder perspective).
- Blob: A blob (Binary Large Object) is the object type used to store the content of each file inserted into the repository. A blob is only aware of the content it stores — it's even unaware of what file it represents! Hence, a single blob can technically serve as a blueprint for any amount of files in the repository. A blob cannot reference any other object and is thus always a leaf in the DAG.
Storing a snapshot
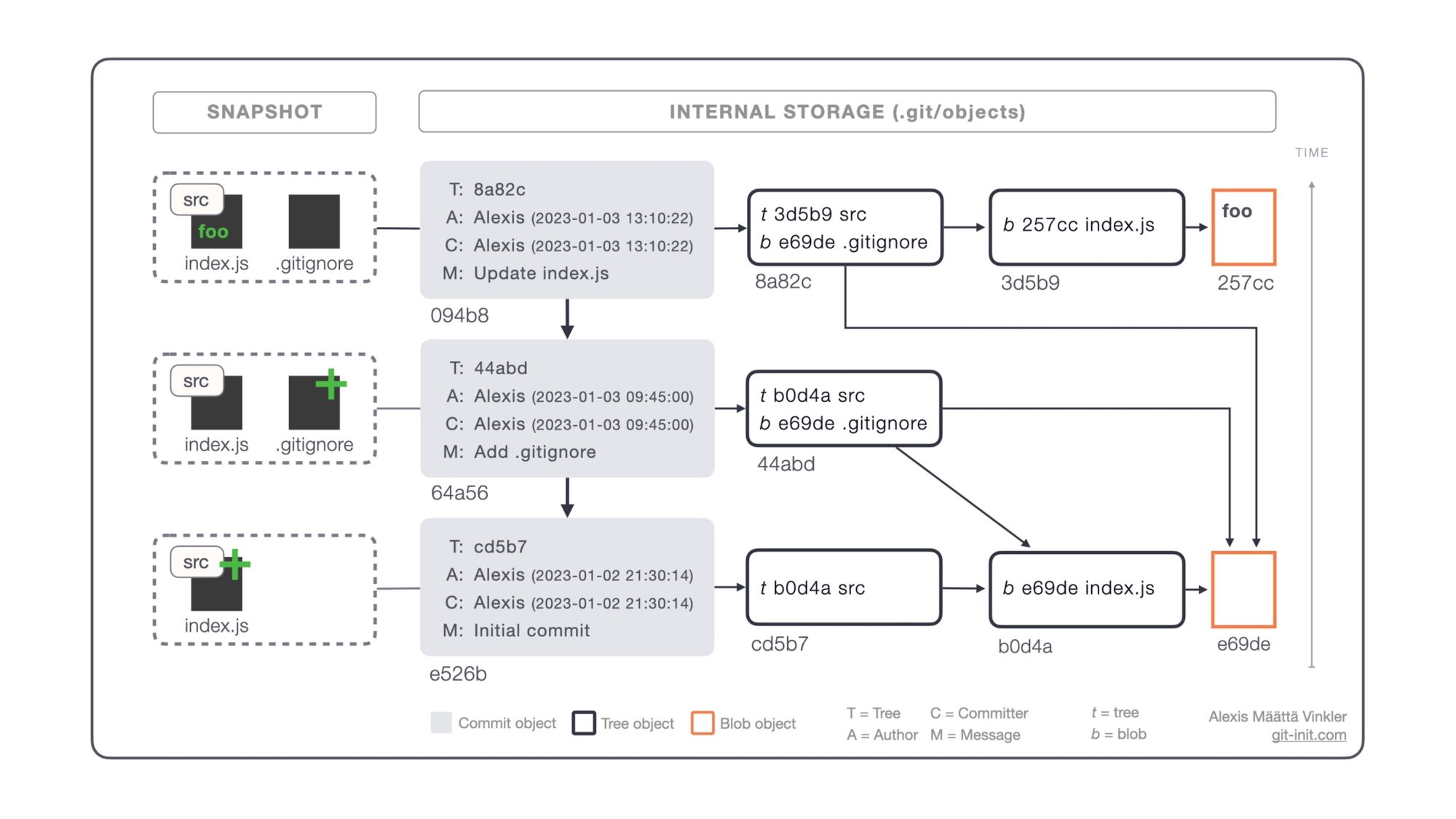
With the background and fundamentals covered, we are now ready to answer our main question "How does Git store files?" — lets view it from a regular commit action perspective!
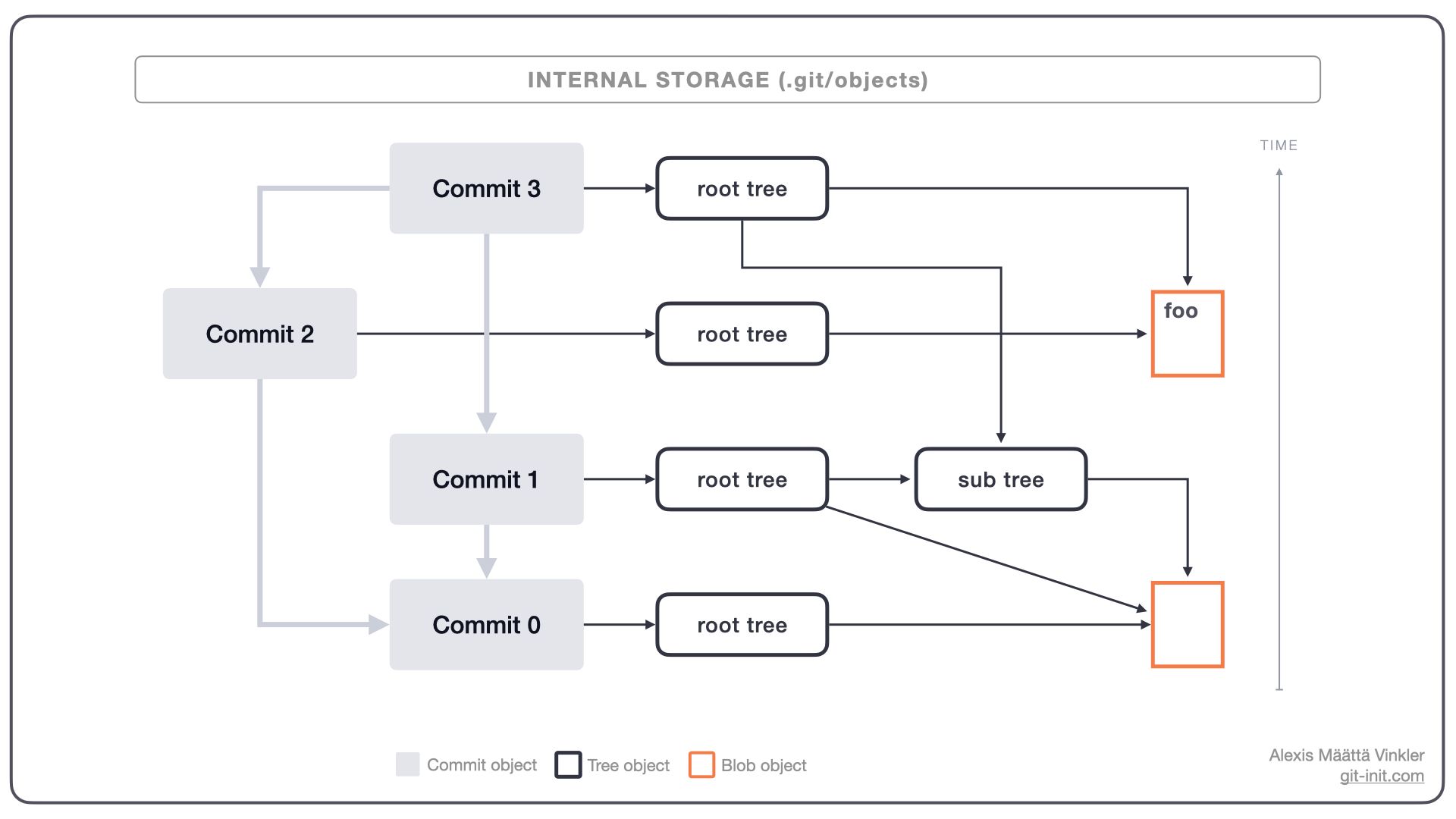
In the above illustration, we have the same history as demonstrated earlier, but the main difference is that the trees and blobs storing our project snapshots are also visible. As you can see each individual commit holds exactly one reference to a root tree, from which the entire snapshot can be reproduced (by following the arrows downstream).
When Git stores a new commit, it first needs to persist the state of all your files (and indirectly your folders), before the root tree reference can be computed and handed back as input to the commit creation process.
The algorithm for storing files and folders looks roughly as follows:
- Hash the content of each file, and check if a blob already exists in the dictionary (
.git/objects) otherwise, add a new blob using the generated hash as its key. This process happens as soon as theaddaction is performed, i.e. when you stage a file. - Create a tree for each project folder, starting from the deepest one in the hierarchy, by adding all previously generated direct child references (blobs or trees) with their respective names as input upon creation. Repeat until the project's root folder is reached, from where the root tree can be finally generated.
- Hand back root tree reference to commit object creation.
Below is the above process described in concrete terms for one initial commit storing a single empty file in the following path: ./src/index.js
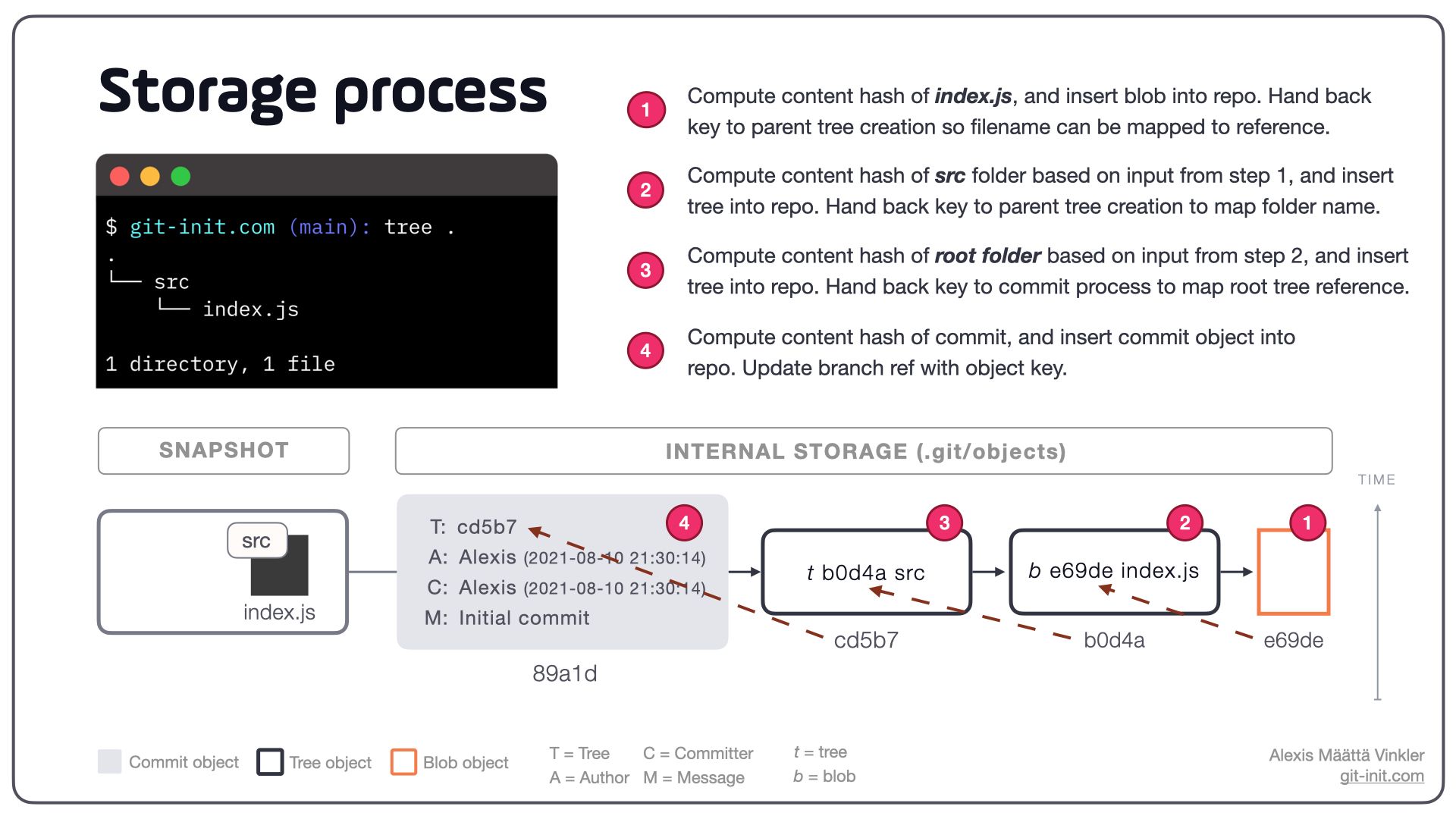
By hashing all objects inserted into the repository, and using the resulting hash as the key to the object inserted, data integrity at its highest level is achieved. This process also ensures no duplicate data is ever stored since the computed key can easily be used to verify if data about to be inserted already exists — and hence simply use the existing reference instead.
Key takeaways
From a high-level perspective, you don't have to worry about blobs and trees as Git creates them automatically as part of the commit process. But what's important to understand is that each object in the DAG structure, in which your files and folders are broken up and stored, is immutable — just like all commits!
In Git, project files are first class citizens and folders second class. Don't agree? Create an empty folder and try toaddandcommitit — Nothing will happen, Git won't let you do it!
Things to note about Git's internal storage:
- Content is key 🤓
- Project files and folders are stored using a sequence of blob and tree objects forming a DAG structure
- All objects are individually hashed and their respective checksum is used as a key in Git's giant dictionary — making them all immutable. This logic also enforces data integrity and prevents duplicates!
- Each commit refers to one root tree capable of restoring the entire project snapshot just as it looked at the time of commit
- Commits, Trees, and Blobs are all stored in the structure of a DAG where references between objects only flow in one direction; hence, any blob and tree can be referenced by any number of trees.
- Since the checksum of a tree is computed based on the checksums of its direct subtrees or blobs, a single tree specifies uniquely a whole subset of the snapshot, with full contents.
Want to see how Git stores project files and folders from a concrete step-by-step perspective over multiple commits? Don't forget to sign up, and get instant access to this follow-up post!
😎 Thanks for reading and good luck improving your source code management skills!
If you'd like more pieces like this, make sure to subscribe to the news feed so you don't miss anything!
Any questions or suggestions, try reaching me on Twitter – @Stjaertfena