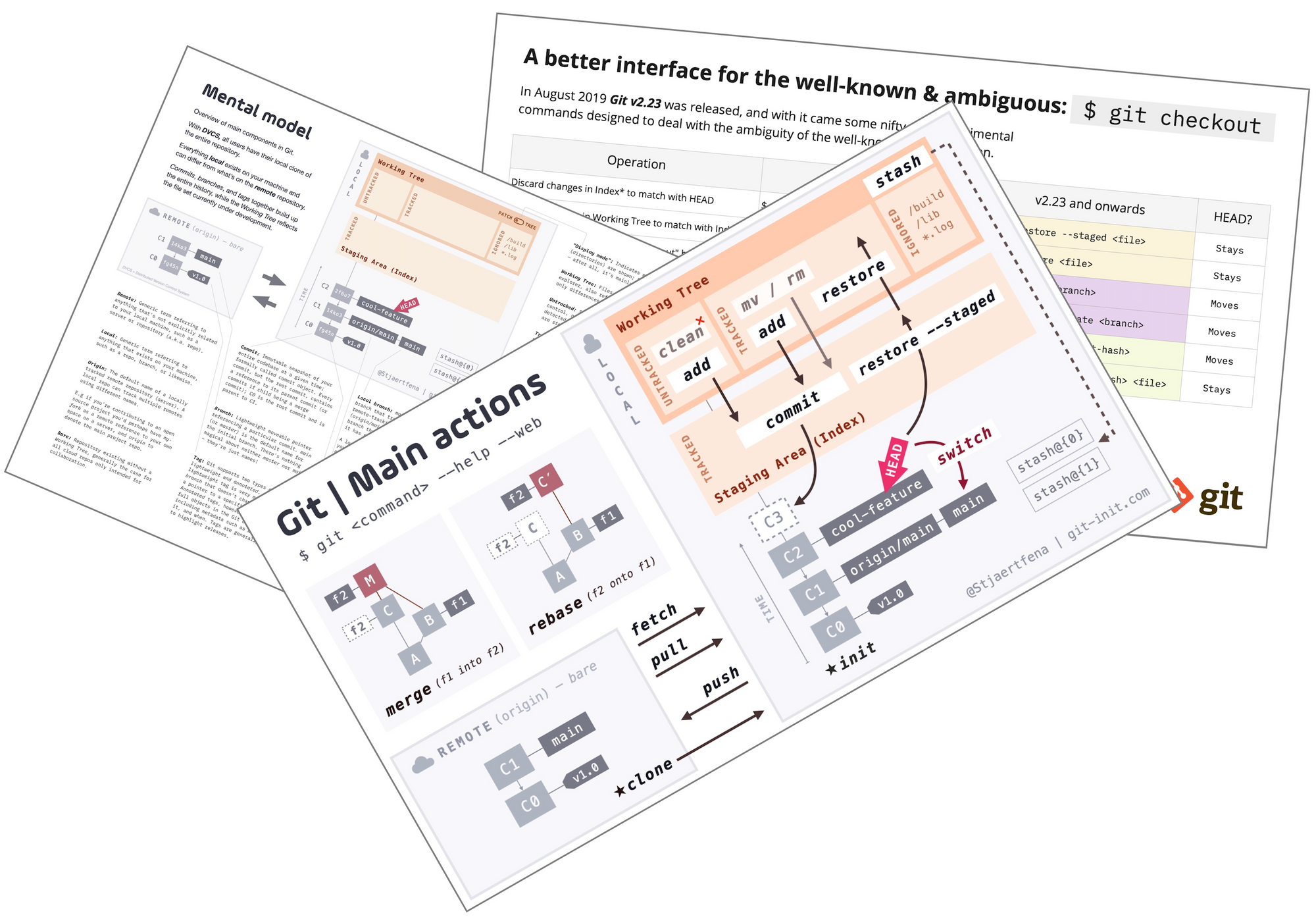
Differences Between Git Merge and Rebase — and Why You Should Care
A comparison of git merge and rebase commands and when to use them!


Regardless of which branching strategy your project is using, integrating code changes between branches is something that you need to do almost daily. With git there are two main options for this, either you merge, or you rebase.
In this post, I’ll illustrate and highlight the differences between the two options and point out things to look out for when performing the actions.
First, I’ll go through the two operations in isolation using animations, finishing with a side-by-side comparison. If you know how the actions work, feel free to skip to the comparison section.
Reading the official Git manual states that rebase "reapplies commits on top of another base branch”, whereas merge "joins two or more development histories together”. In other words, the key difference between merge and rebase is that while merge preserves history as it happened, rebase rewrites it. Before we look at their inner workings to understand what this means, let’s start with an example!
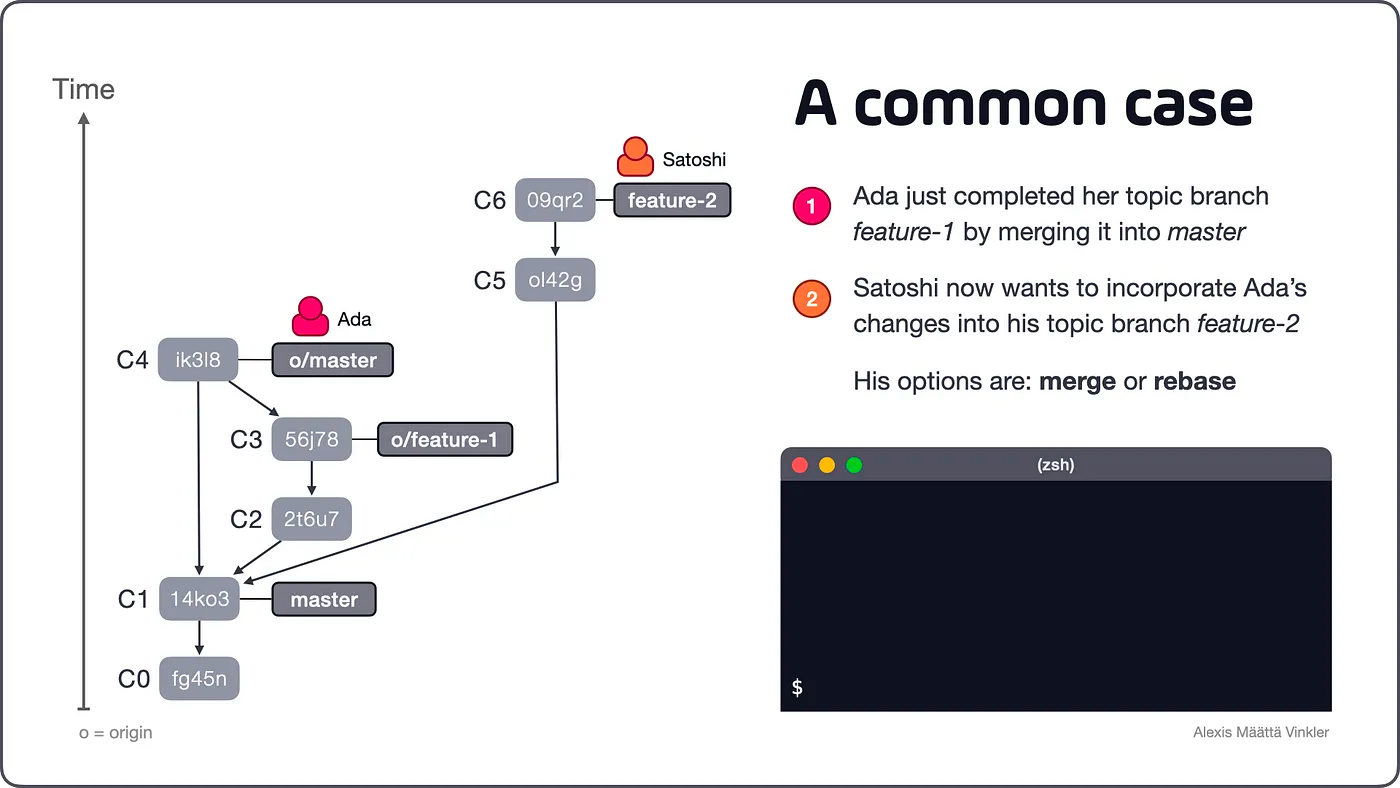
Looking at the example above, we see that the developers Ada and Satoshi initially created two topic branches (feature-1 and feature-2), stemming from the same commit (C1) on the master branch. Ada then completed feature-1 by merging it into master (creating merge commit C4). Satoshi now has two options to integrate Ada’s changes into his branch feature-2 — merge or rebase.
Merge
Let’s start with the most common workflow for integrating changes: merge. Before Satoshi is ready to merge Ada’s changes into feature-2, he must first update his local master reference, as it’s currently trailing behind. Once master and o/master are in sync, Satoshi is ready to merge everything into his topic branch.
Checkout this 30-second animation illustrating the process:
Animation illustrating the merge workflow. (Video only, no audio)
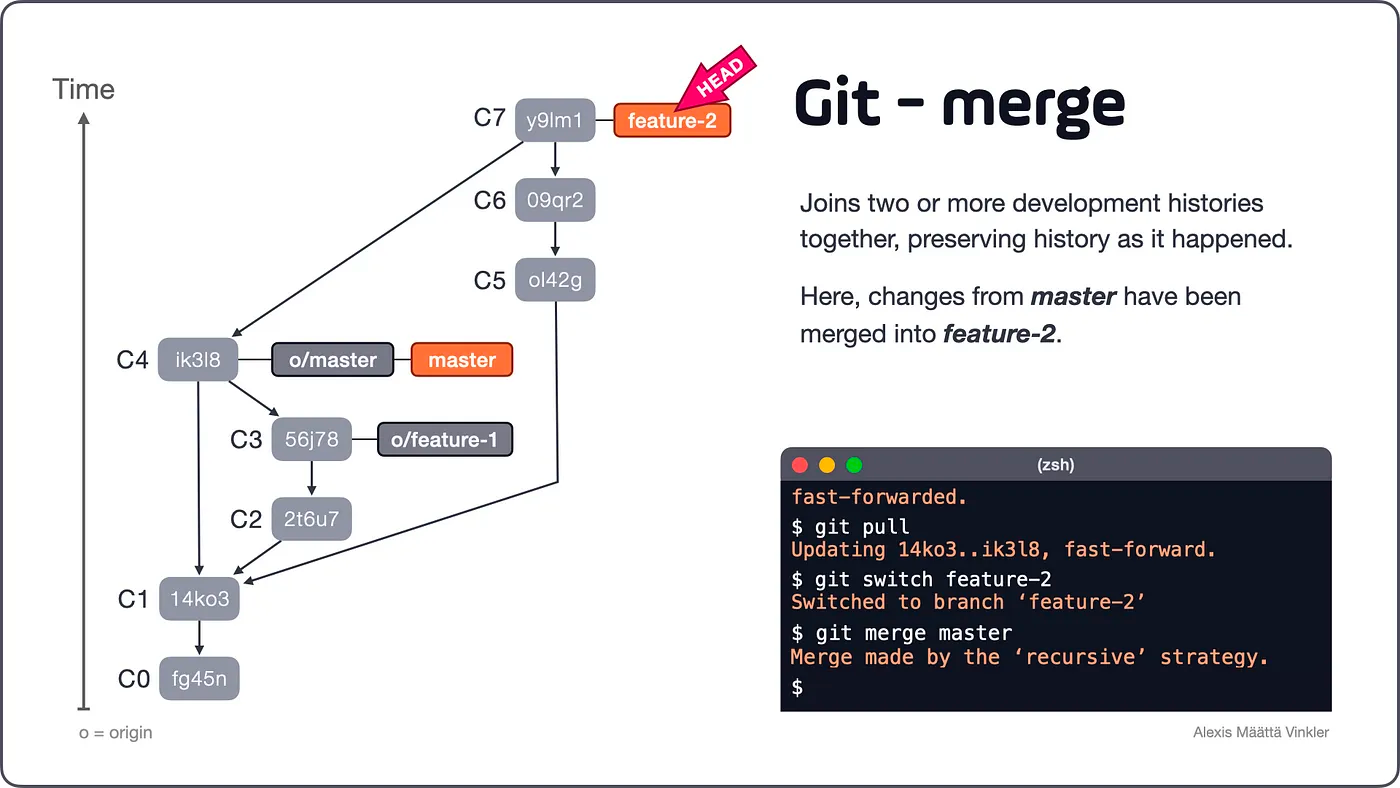
With all changes merged into feature-2 Satoshi can now continue to develop the branch, finishing it off by merging it back into master whenever it’s completed.
Below is the final result from the merge action. As you can see, the development history is preserved just as it happened, with only C7 added.
Confused by the moving HEAD pointer? Checkout this post on the subject!

Rebase
With the basic merge workflow in mind, it’s time to look at the same example but from a rebase perspective. Just as in the merge case, he must first ensure his local and remote branches are in sync before Satoshi can integrate the changes. But then, instead of making a regular merge “preserving history as it happened”, Satoshi can instead integrate all changes using rebase and hence “rewrite history”.
By rebasing feature-2 onto master Git will rewind and reapply the commits C5 and C6 one by one, straight onto C4, making it look like feature-2 was originally branched off the tip of Ada’s completed changes.
Checkout this 30-second animation to see the process in action:
Animation illustrating the rebase workflow. (Video only, no audio)
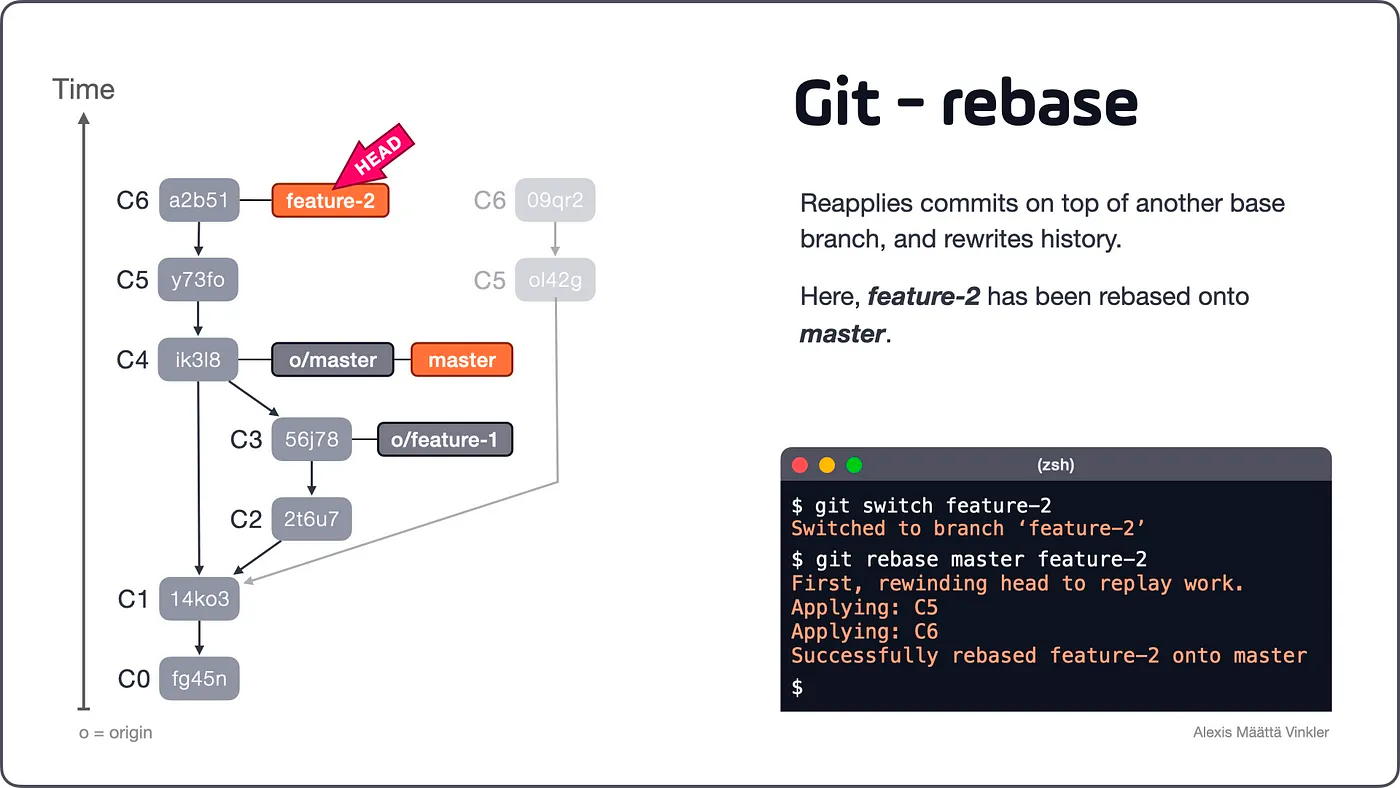
With all changes again integrated, Satoshi is ready to continue working on his topic branch.
Below is the final result from the rebase action. Notice how commits C5 and C6 have been reapplied straight onto C4, rewriting the development history and deleting the old commits completely!
Now that we know how merge and rebase differ, it’s time to scrutinize the two outcomes in more detail.
As a member you'll also get instant access to other downloadable resources tailored to help you excel with Git!

🍿 Laptop stickers
Hook yourself up with a pack of stickers, and never forget the difference between merge and rebase again!
How Merge and Rebase Differ
A side-by-side comparison of the two operations.
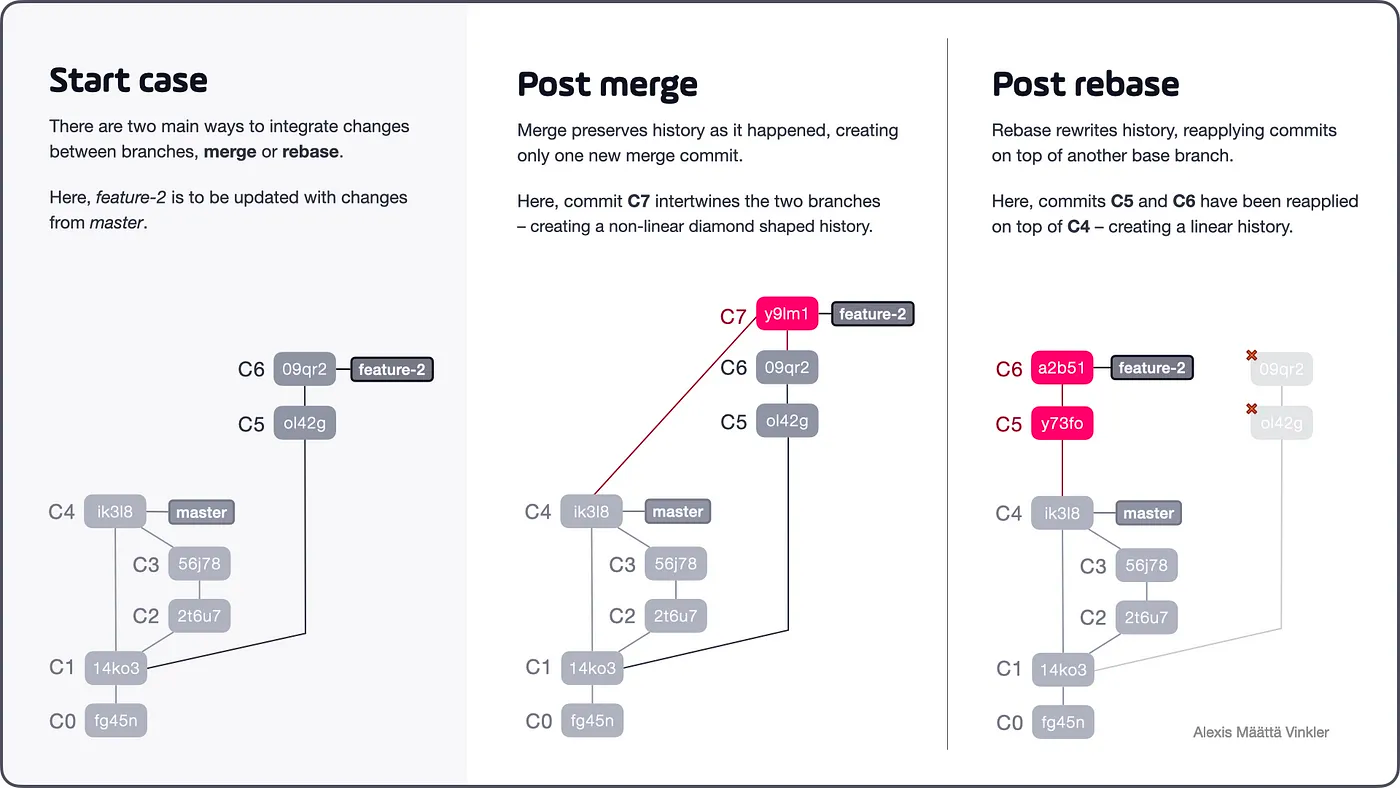
As we can see above, the merge operation intertwined the branches together by creating a new single merge commit (C7), causing a diamond-shaped non-linear history — essentially preserving history as it happened. By comparing this result with the outcome from the rebase action, we see that no merge commit was created, instead the two commits C5 and C6 simply got rewinded and reapplied straight on top of C4, keeping the history linear. If we scrutinize the two reapplied commits further, we can see that the hashes have changed, indicating that rebase truly rewrites history.
With Great Power Comes Great Responsibility
We’ve seen how rebase rewrites history while merge preserves it. But what does this mean in a broader sense? And what possibilities and potential drawbacks do the two operations come with?
Conflicting changes
Let’s say, for example, you’ve had some nasty conflicts trying to integrate changes. In the merge scenario, you would have only needed to solve the conflicts once, straight in the C7 commit. With rebase, on the other hand, you could potentially have been forced to solve similar conflicts in each commit (C5 and C6) as they got reapplied.
If conflicts aren’t so straightforward to solve, it may be a sign that you and your colleagues have not been communicating enough, as you’ve been working on the same files for too long.
Published branches
Another potential problem related to rebase occurs when the branch you are rebasing has already been published remotely, and someone else has based their work on it. Then, your rebased branch can cause serious confusion and headaches for all involved parties, as Git will tell you that your branch is both ahead and behind simultaneously. If this happens, pulling remote changes using the rebase flag (git pull --rebase) generally solves the problem.
Furthermore, whenever you are rebasing an already published branch, regardless if no one else has based their work on it, you’ll still need to force push it to get your updates to the remote server — overwriting the existing remote reference completely.
Loss of data (to your advantage)
Finally, as rebase rewrites history while merge preserves it, it’s possible actually to lose data when rebasing. When new commits are reapplied, the old ones are (eventually, post garbage collection) deleted. This same trait is, in fact, what makes rebase so powerful — it allows you to tidy up your development history before making it publicly available!
Using interactive rebase, you can, for example, remove unwanted commits, squash changes together, or update commit messages. Here's a post on that, How to Tidy up a Dirty Commit History.
Rebasing Rules of Thumb
To avoid the most common issues related to rebase, I’d suggest sticking to the following rules:
- Don’t rebase a branch that’s been published remotely…
- …unless you know you are the only one working on it (and feel safe force-pushing)
- Before rebasing, create a backup branch from the tip of the branch you’re about to rebase, as it will allow you to easily compare the outcome (once done) and jump back to the pre-rebase state if necessary – instead of digging it out from the reflog.
Conclusion
Many developers tend to only use merge over rebase, generally with the comment, “At least I know I won’t lose any work.” In a sense, it’s a solid approach to not use tools you aren’t comfortable working with. But, not learning to take full advantage of powerful features, even though you know they exist, isn’t such a good approach!
It’s a bit like saying, “I know I have this awesome car, but I prefer to stick to the first gear, as I know speed kills.”, rather than learning how to shift up and get comfortable traveling safely at higher velocities.
In my experience, learning how to use rebase deepens your understanding of Git in particular and improves you as an overall developer in general — especially concerning source code management!
Finally, one of the best pieces of advice I ever got from a senior developer early in my career was this: “Drop the button bashing in Source Tree and learn how to use the Git commands from the terminal instead! Otherwise, you’ll never get the full benefit of using Git, and you won’t be able to script any automation pipelines later on.”
Since then, I’ve only used GitK as a visual aid for inspecting the history graph. I type all commands in the terminal. I suggest you do the same!
Now that you know how merge and rebase differ, I hope you feel more confident in using them.
😎 Thanks for reading, and good luck improving your source code management skills!
If you have any questions or suggestions, try reaching me on Twitter – @Stjaertfena