How to Tidy up a Dirty Commit History (squash vs fixup)
Got some unwanted files, changes, or commit messages in your history? Don't worry! In this post I'll show you how to tidy up a dirty commit history.


Whenever I start to work on something new, whether it's a complex problem, a small prototype, or a new framework, taking on a trial and error approach is generally what works best for me. However, this way of working indirectly produces a polluted commit history, as I spend little time crafting my commits – I only want to plow ahead as fast as I can.
In this post I'll show you how you can tidy up your own dirty commit history, so you don't have to think twice before creating those temporary commits ever again!
Even if you're not using this trial and error approach yourself, I'm pretty sure you can still reconcile with the need to sometimes wanting to rework commits (for various reasons). Regardless, I'm certain you'll be able to follow along through this case study, and learn how to tidy up a dirty commit history.
A typical case
Let's say we've been working on a feature branch trying to get some kind of project configuration working (maybe a build sequence, or perhaps a web server). Below is a typical case illustrating this, where experimental commits have been made leading up to a working solution; the history though looks a bit messy, just look at some of the commit messages!
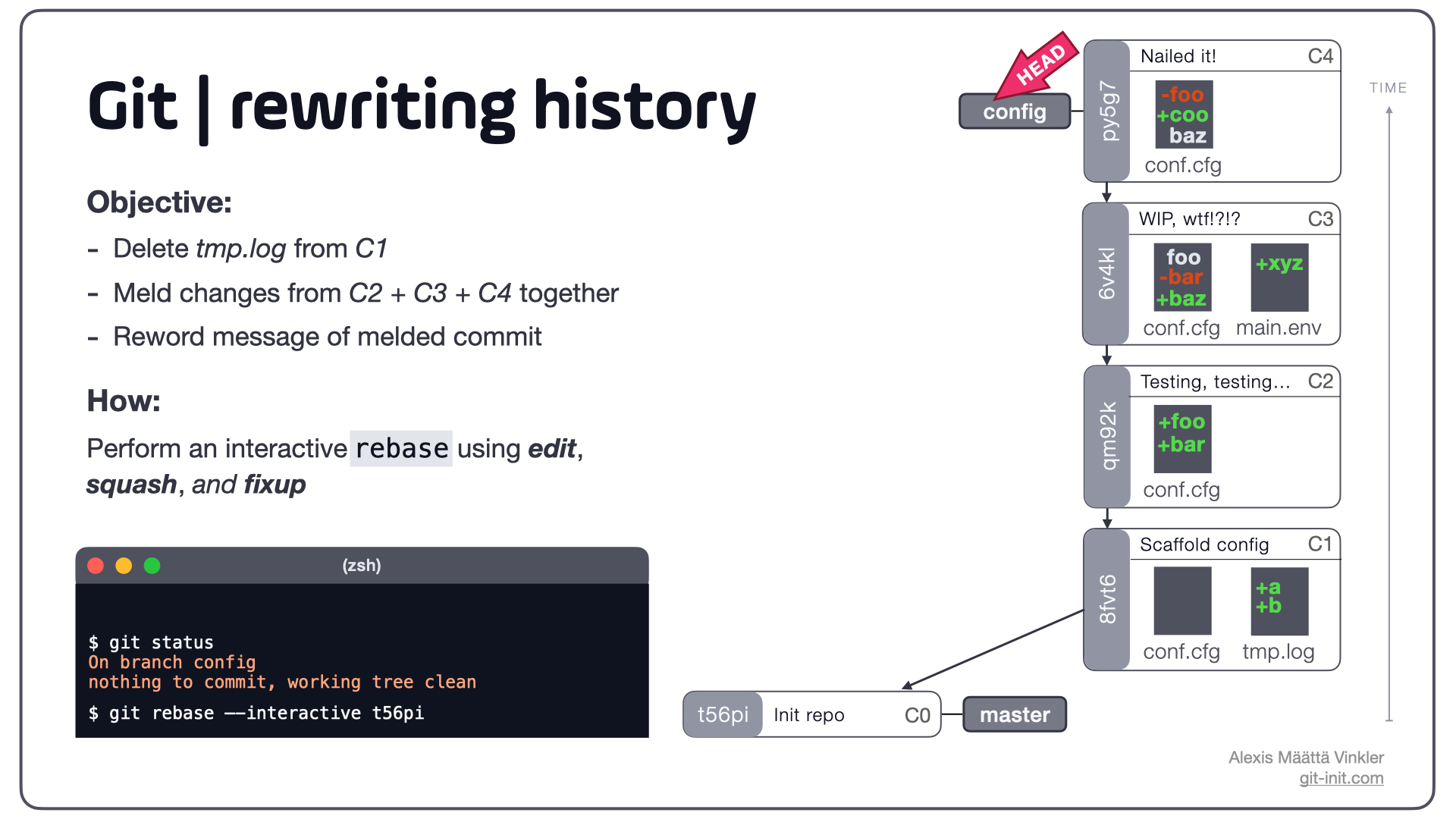
In the illustration four commits have been made on a feature branch named config, using somewhat of an trial and error approach – trying to get the configuration working. In commit C1 the file tmp.log was accidentally added, and in the sequence C2-C3 experimental changes were made. With the final changes in C4 everything eventually started to work. The branch is now ready to be merged with master but should first be tidied up.
Let's look at how to rewrite history and remove the unwanted file and tidy up the commits altogether, ultimately fixing the bad commit messages and producing a useful history.
Rewriting history with interactive rebase
Given our case from above, we're able to start the process of tidying our history using an interactive rebase, targeting commit C0 (t56pi) as the source to base our new history on (notice it's the same point our current history is based on).
$ git rebase --interactive t56piWhen issuing the above command, Git opens a temporary file (git-rebase-todo) in your editor (generally vi if you've not changed your default configuration) to allow you to specify exactly what to do with each commit. By default all commits in the range are marked with pick, meaning "use commit as is". Below is the rebase-todo file illustrated – notice how the commits are listed in reversed order compared to the history on the right hand side.
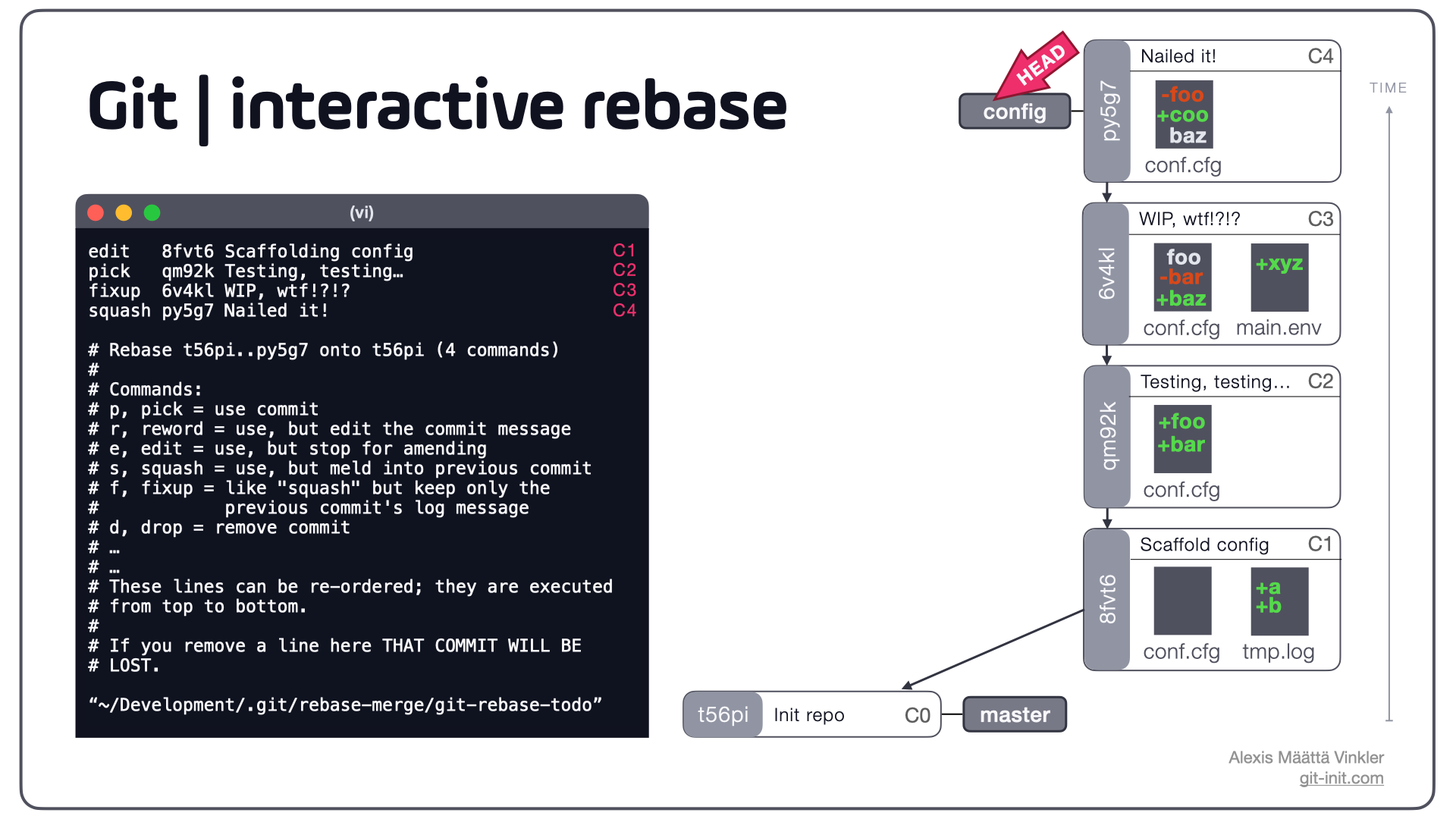
As the documentation inside the rebase-todo file displays, there are numerous commands to choose from.
Since we'd like to remove tmp.log from C1, the first line is marked with edit (e.g. stop for amending). In order to meld C2 + C3 + C4 together and reword the final commit message, fixup and squash have been selected for C3 and C4 respectively.
The difference between squash and fixup, is that squash let's you edit the resulting commit log message; fixup, on the other hand, defaults to using the previous commit's log message.
With the desired commands selected, saving and closing the file starts the interactive rebase process.
Here is what will happen:
HEADis moved back in detached state to C1, where the process is halted.- The unwanted file can now be removed with
$ git rm ./tmp.logand the change automatically amended to the current commit by continuing the process with$ git rebase --continue. (This will create a new commit C5, with C0 as its parent, containing the changes from C1 but with the log file removed). - As the process continues, Git melds all changes in C2 + C3 + C4 together, automatically discarding the commit message from C3, and prompts us with the option to manually edit the final commit message – in this case rewording it to "Enable config" – before automatically creating a new commit C6 with C5 as its parent.
- Finally Git moves the config branch pointer to C6 and finishes off by reattaching
HEADto config. All done!
Below is the final state, post rebase, with the original commits on the far right.
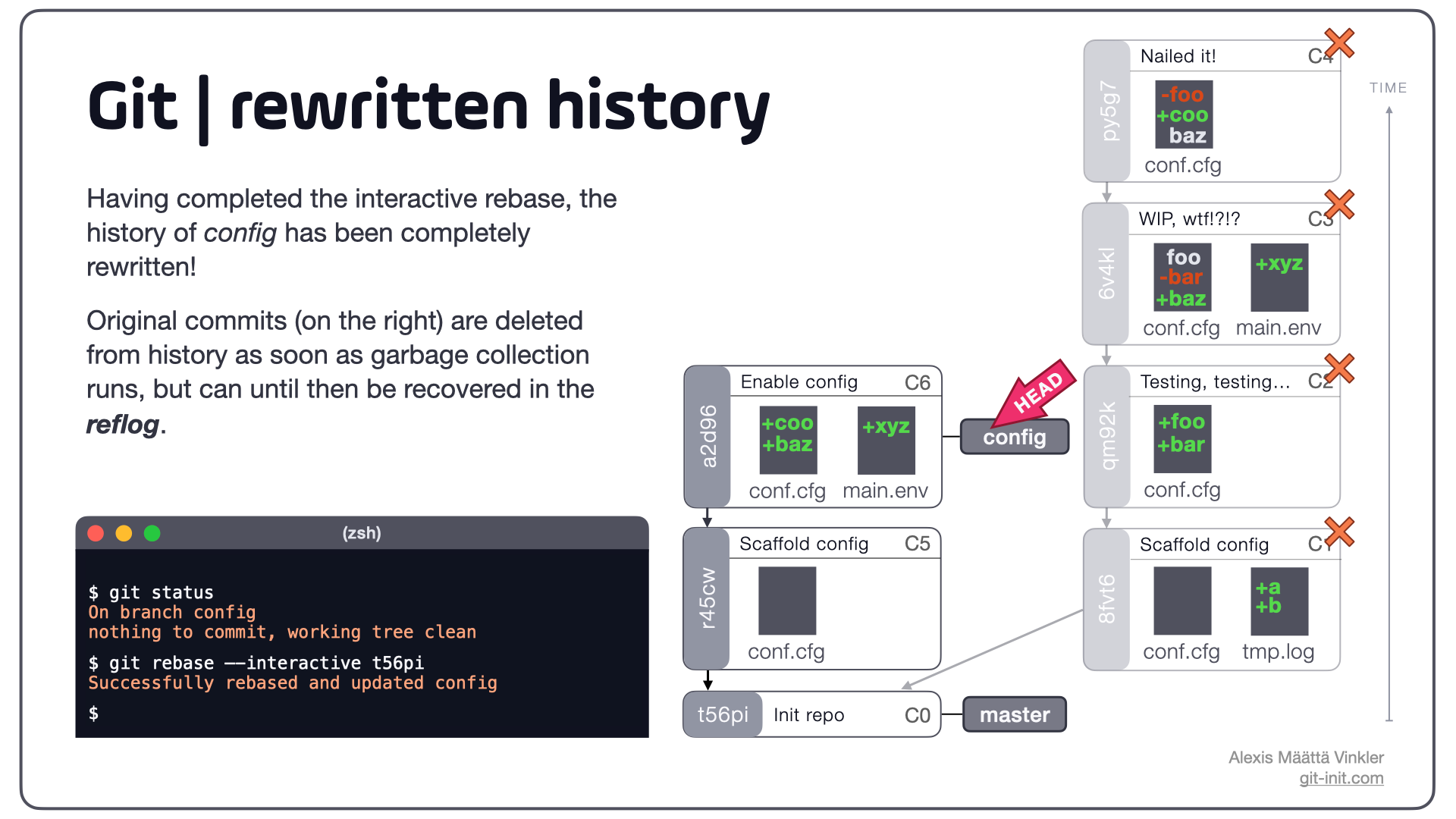
Notice how our newly rebased config branch now only contains the desired changes:
- In C5,
tmp.logis no longer present, but everything else is kept from C1 - C6 only has the relevant changes from C2, C3, and C4, including a proper commit message
- config is moved from C4 to C6 and
HEADis reattached to once again point to the config branch
The original commits (C1, C2, C3, C4) still exist in our local repo and can be accessed through the reflog if needed; eventually they'll all be deleted as soon as garbage collection runs.
If you're struggling to comprehend why C5 and C6 got introduced as new commits, instead of C1 and C2 being "updated", I suggest you revisit this post on commits being immutable snapshots.
With our config branch tidied up, it can now be shared with the rest of the world!
Conclusion
Being aware of some of the possibilities rebase entails, when it comes to rewriting history, should hopefully allow yourself to take on a more relaxed approach to committing – knowing that you can easily tidy up a dirty commit history!
With this example I hope you feel even more confident relying on Git as the ultimate "undo on steroids".
Finally
As with all operations related to rewriting history... Unless you know exactly what you're doing and have good communication within your team – only rewrite commits that have not yet been published remotely!
😎 Thanks for reading and good luck improving your source code management skills!
If you'd like more pieces like this, make sure to sign up on the news feed so you don't miss anything!
Any questions or suggestions, try reaching me on Twitter – @Stjaertfena