Git Commands & Concepts – Demystified (part 2)
Being overwhelmed by Git's commands & concepts is unfortunately not too uncommon. This second post in the small series, aimed at making your life with Git more durable, focuses on managing files locally!

This is the second post (out of three) in the short series demystifying common commands and concepts with Git. In the previous post we looked at all main entities of Git worth knowing. In this post we'll instead focus on understanding workflows which manipulates these entities.
Familiarising yourself with below concepts and actions will for sure aid you in your day-to-day Git usage. 🚀
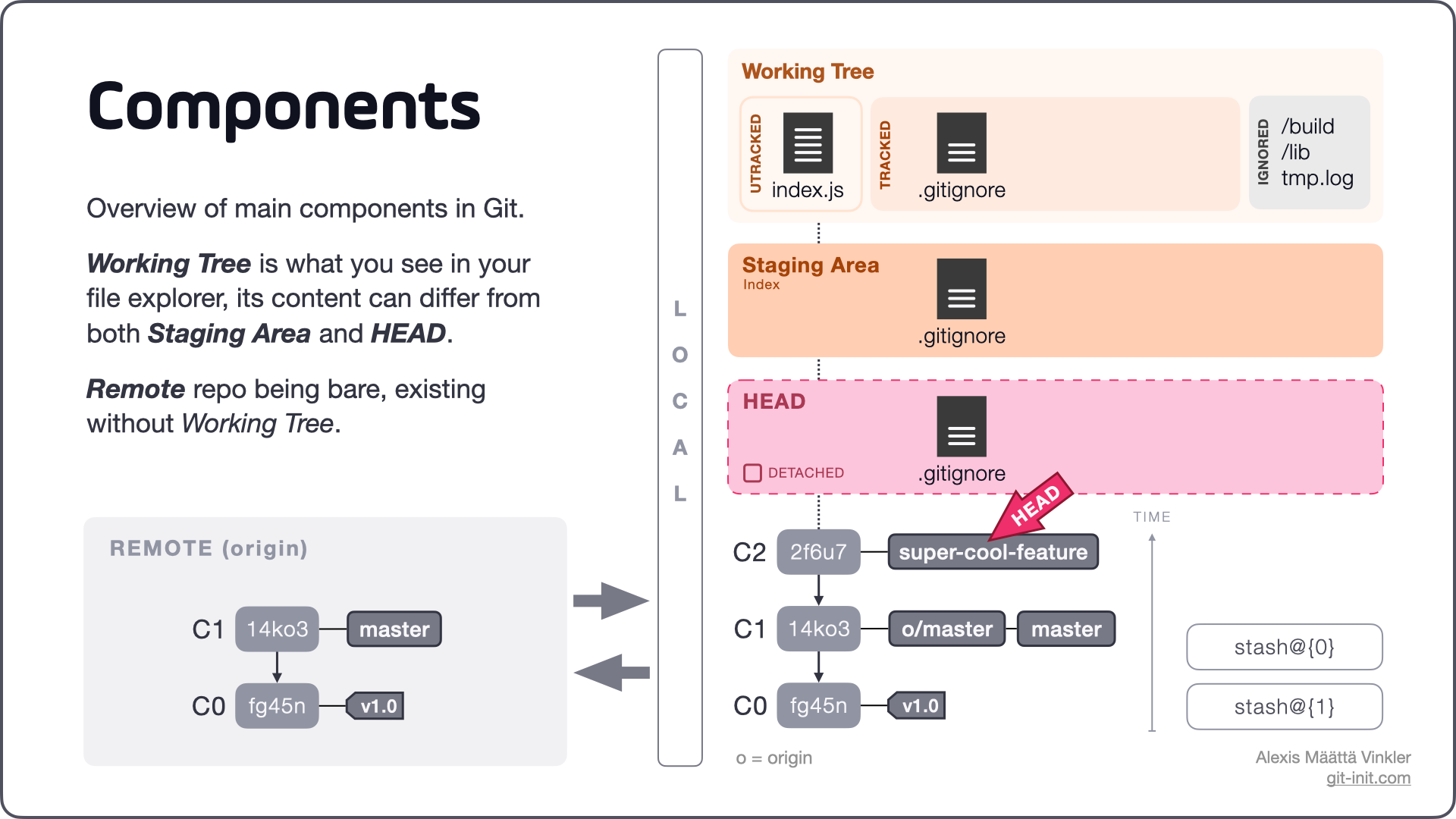
Remote vs Local
Most of the commands performed in Git happen locally (offline) without any connectivity between the remote and local repositories; you can even work completely without a remote counterpart! In essence, only clone, fetch and push are commands that send and receive data between a local and remote repository; the rest of the commands only manipulate data locally.
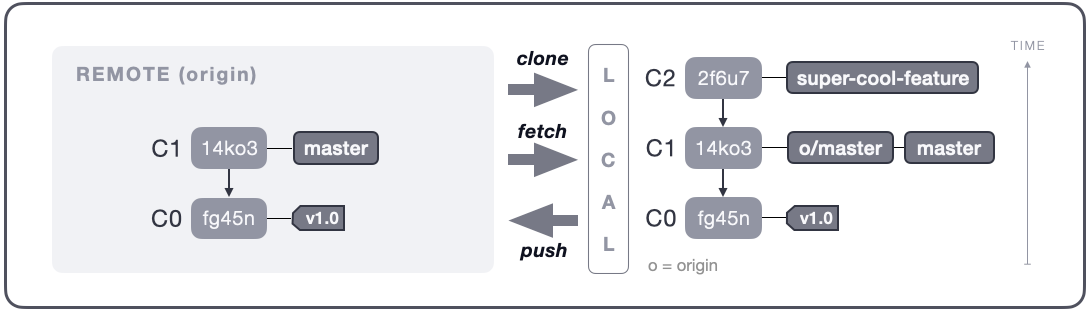
- Clone: Copies an entire remote repository down to your local machine, setting up a cloned version and checks out the default branch (generally master); this action is done only once.
- Fetch: Updates remote references in your cloned local repository. E.g. if a developer has pushed changes to a remote branch, those changes will be pulled down to your repository whenever fetch is performed. Note: fetch won't automatically merge any changes, only update references.
- Push: Makes your local changes publicly available in a remote repository. E.g. the most basic way of sharing work with team members.
With the above simple workflow in mind, let's continue digging into the actual work happening locally, starting with the file states.
Local file states
With Git, all files in your project will be in either of three main states: untracked, tracked, or ignored; where ignored files are essentially explicitly untracked. Furthermore, as for all tracked files Git also keeps track of more specific states related to these, such as modified or deleted. Let's take a closer look!